Normalerweise möchte man, dass die Website – egal ob privat oder geschäftlich – von möglichst vielen Menschen im Internet gefunden und besucht wird. Gute Sichtbarkeit und gutes Ranking sind die obersten Ziele bei der Suchmaschinenoptimierung. Es gibt jedoch Situationen, in denen die Website nicht für die Öffentlichkeit sichtbar sein sollte. Das kann eine Portfolio-Website sein, die man lediglich als Referenz bei Bewerbungen oder bei Business-Portalen wie LinkedIn angibt. Meine Portfolio-Website gehört dazu. Auch bestimmte Unterseiten, die den Leser:innen keinen Mehrwert bieten, sind für die Suchergebnisse irrelevant. In diesem Artikel erkläre ich, wie du Suchmaschinen davon abhältst, einzelne Seiten oder die gesamte Website zu indexieren.

Was ist der Index einer Suchmaschine?
Der Index einer Suchmaschine ist das zentrale Element, das eine effiziente und präzise Bereitstellung von Informationen bei Suchanfragen ermöglicht. Dieser Index funktioniert wie eine riesige Datenbank, die alle relevanten Informationen und Inhalte von Webseiten speichert, die die Suchmaschine während ihres Durchsuchungsprozesses im Internet findet. Dabei gleicht er einem digitalen Inhaltsverzeichnis, das die Seiteninhalte strukturiert und organisiert, um bei Anfragen sofort die passenden Ergebnisse liefern zu können. Der Index ist daher nicht nur ein passiver Speicher, sondern eine dynamische und intelligente Datenbank, die permanent aktualisiert wird und eine grundlegende Basis für die Relevanzbewertung von Webseiten bietet.
Damit eine Suchmaschine ihren Index aufbauen und ständig aktuell halten kann, kommt ein spezielles Programm namens Crawler zum Einsatz. Dieser Crawler, auch als Bot oder Spider bezeichnet, ist ein automatisiertes Tool, das das Internet kontinuierlich durchsucht. Der Crawler „besucht“ Webseiten, folgt den dort enthaltenen Links und sammelt Informationen über den Seiteninhalt, Metadaten wie Titel und Beschreibungen sowie weitere für die Suchmaschine relevante Details. Sobald der Crawler eine Seite durchsucht hat, werden ihre Inhalte an das Indexierungssystem der Suchmaschine weitergeleitet.
Das Indexierungssystem verarbeitet die gesammelten Daten und fügt sie in den Index ein. Dieser Prozess umfasst eine inhaltliche Analyse der Seite, bei der die Suchmaschine feststellt, welche Schlüsselwörter und Konzepte auf der Seite vorkommen, und die Daten dann strukturiert speichert. Ein komplexes Bewertungssystem sortiert die Seiten nach verschiedenen Kriterien wie Relevanz, Aktualität, Inhaltstiefe und Glaubwürdigkeit. Die Algorithmen der Suchmaschine spielen hierbei eine entscheidende Rolle, da sie bestimmen, welche Seiten für welche Art von Suchanfragen angezeigt werden. Zusätzlich findet ein kontinuierlicher Abgleich statt: Webseiten, die regelmäßig aktualisiert werden, werden auch häufiger vom Crawler überprüft, um sicherzustellen, dass der Index stets die aktuellsten Daten enthält.
Suchmaschinen-Indexierung verhindern: Diese Möglichkeiten gibt es
Um die Suchmaschinen-Indexierung einer Website zu verhindern, gibt es verschiedene Methoden, mit denen Website-Betreiber sicherstellen können, dass bestimmte Inhalte nicht in den Index einer Suchmaschine aufgenommen werden.
robots.txt-Datei
Die „robots.txt“-Datei ist eine Textdatei, die im Stammverzeichnis einer Website abgelegt wird. Sie gibt Suchmaschinen-Bots Anweisungen, welche Seiten oder Verzeichnisse sie crawlen und indexieren dürfen und welche nicht. Ein Beispiel für eine „robots.txt“-Anweisung, die den Zugriff auf eine Seite verhindert, sieht so aus:
User-agent: *
Disallow: /beispielseiteDiese Einstellung teilt allen Crawlern („User-agent: *“) mit, dass die Seite „/beispielseite“ nicht gecrawlt werden soll.
Meta-Tags „noindex“
Über das Meta-Tag „noindex“ im HTML-Quellcode der Seite kann eine Anweisung hinzugefügt werden, die verhindert, dass die Seite im Index der Suchmaschine gespeichert wird. Das „noindex“-Tag wird im Header der Seite platziert und sieht so aus:
<meta name="robots" content="noindex">So habe ich den Tag in meiner Website eingebaut:
<head>
<meta charset="UTF-8">
<meta name="description" content="Portfolio- und Entwicklungssite von Sladjan Lazic">
<meta name="author" content="Sladjan Lazic">
<meta name="publisher" content="Sladjan Lazic">
<!-- robots noindex für Crawler = keine Google-Indexierung! -->
<meta name="robots" content="noindex">
<link rel="icon" href="favicon.ico">
<link rel="stylesheet" href="style.css">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Sladjan Lazic Webdesign</title>
</head>Diese Anweisung sagt den Suchmaschinen, dass sie die Seite nicht indexieren sollen, selbst wenn sie gecrawlt wird.
HTTP-Header „X-Robots-Tag“
Der „X-Robots-Tag“ ist eine Anweisung, die im HTTP-Header der Seite angegeben wird und eine Alternative zum Meta-Tag „noindex“ darstellt. Dieser Ansatz eignet sich besonders für Dateien oder Inhalte, bei denen kein direkter HTML-Zugriff besteht (z. B. PDF-Dateien). Ein Beispiel für den Header sieht so aus:
X-Robots-Tag: noindexPasswortschutz
Wenn Seiten durch einen Passwortschutz geschützt sind (etwa über HTTP-Authentifizierung), verhindert dies den Zugriff der Suchmaschinen-Crawler auf die Seiteninhalte. Diese Methode ist eine der sichersten, da der Zugriff auf den Inhalt nur nach Eingabe des Passworts möglich ist, wodurch die Seite auch für die Crawler unzugänglich bleibt.
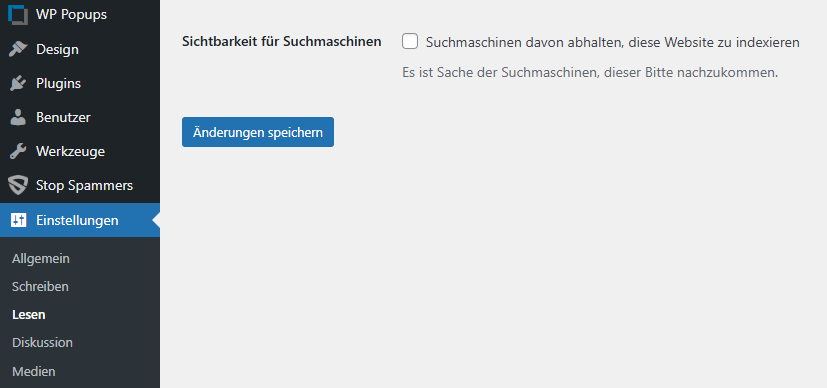
Einstellung in WordPress
In WordPress lässt sich unter Einstellungen > Lesen > Sichtbarkeit für Suchmaschinen im Backend ein Häkchen setzen, um Inhalte vom Suchindex auszuschließen. Die meisten Suchmaschinen folgen dieser Anweisung in der Regel. Trotzdem bleibt es letztlich den Suchmaschinen überlassen, dieser Aufforderung tatsächlich nachzukommen – darauf weisen auch die WordPress-Entwickler hin: „Es ist Sache der Suchmaschinen, dieser Bitte nachzukommen.“ Wichtig zu wissen ist zudem, dass die Seite dennoch von den Crawlern der Suchmaschinen besucht und analysiert werden kann.
Suchmaschinen-Indexierung verhindern – Fazit
Wir haben uns verschiedene Möglichkeiten angeschaut, wie man seine Website von der Suchmaschinen-Indexierung ausschließen kann. Es ist eine hilfreiche Maßnahme, um bestimmte Inhalte vor der Öffentlichkeit zu schützen oder die Sichtbarkeit in den Suchergebnissen zu kontrollieren. Obwohl gängige Systeme wie WordPress Optionen bieten, Inhalte von der Indexierung auszuschließen, bleibt die Entscheidung letztlich den Suchmaschinen überlassen, ob sie dieser Aufforderung folgen. Daher solltest du zusätzliche Schritte, wie das Einfügen einer robots.txt-Datei oder noindex-Metatags, in Betracht ziehen, um die Wahrscheinlichkeit einer Nicht-Indexierung zu erhöhen. Es ist jedoch wichtig zu beachten, dass auch bei diesen Maßnahmen Suchmaschinen die Website weiterhin crawlen können, was für viele Anwendungen akzeptabel ist, aber nicht unbedingt völlige Anonymität garantiert.

- Die Geschichte des Webdesigns: Eine Reise durch die digitale Zeit – 25. November 2024
- Suchmaschinen-Indexierung verhindern: So bleibt der Google-Crawler fern – 28. Oktober 2024
- Wie kann man eine Website erstellen?: Ist das der beste Weg? – 20. Oktober 2024
Schreiben Sie einen Kommentar